
亦称: Template Method
模板方法模式是一种行为设计模式, 它在超类中定义了一个算法的框架, 允许子类在不修改结构的情况下重写算法的特定步骤。
假如你正在开发一款分析公司文档的数据挖掘程序。 用户需要向程序输入各种格式 (PDF、 DOC 或 CSV) 的文档, 程序则会试图从这些文件中抽取有意义的数据, 并以统一的格式将其返回给用户。
该程序的首个版本仅支持 DOC 文件。 在接下来的一个版本中, 程序能够支持 CSV 文件。 一个月后, 你 “教会” 了程序从 PDF 文件中抽取数据。
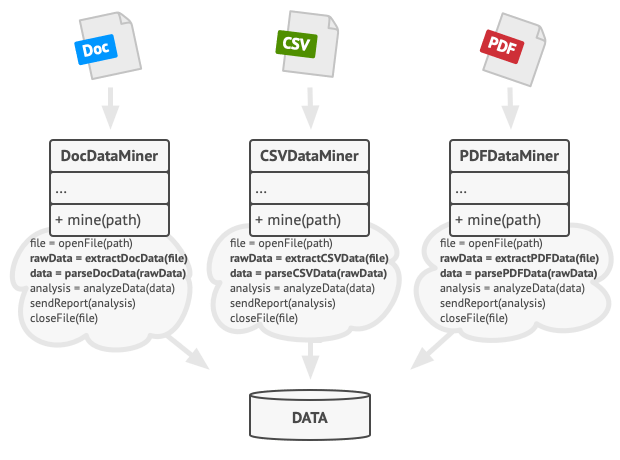
数据挖掘类中包含许多重复代码。
一段时间后, 你发现这三个类中包含许多相似代码。 尽管这些类处理不同数据格式的代码完全不同, 但数据处理和分析的代码却几乎完全一样。 如果能在保持算法结构完整的情况下去除重复代码, 这难道不是一件很棒的事情吗?
还有另一个与使用这些类的客户端代码相关的问题: 客户端代码中包含许多条件语句, 以根据不同的处理对象类型选择合适的处理过程。 如果所有处理数据的类都拥有相同的接口或基类, 那么你就可以去除客户端代码中的条件语句, 转而使用多态机制来在处理对象上调用函数。
模板方法模式建议将算法分解为一系列步骤, 然后将这些步骤改写为方法, 最后在 “模板方法” 中依次调用这些方法。 步骤可以是 抽象的, 也可以有一些默认的实现。 为了能够使用算法, 客户端需要自行提供子类并实现所有的抽象步骤。 如有必要还需重写一些步骤 (但这一步中不包括模板方法自身)。
让我们考虑如何在数据挖掘应用中实现上述方案。 我们可为图中的三个解析算法创建一个基类, 该类将定义调用了一系列不同文档处理步骤的模板方法。
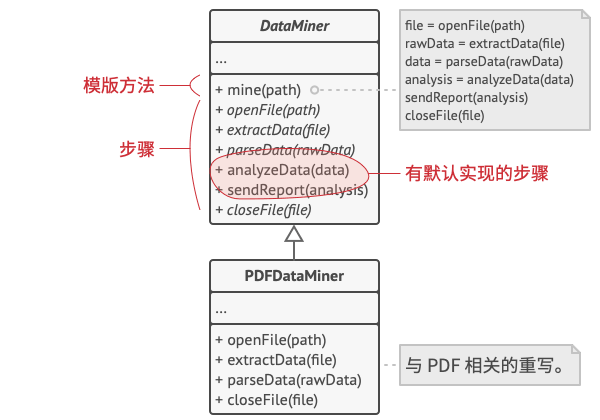
模板方法将算法分解为步骤, 并允许子类重写这些步骤, 而非重写实际的模板方法。
首先, 我们将所有步骤声明为 抽象类型, 强制要求子类自行实现这些方法。 在我们的例子中, 子类中已有所有必要的实现, 因此我们只需调整这些方法的签名, 使之与超类的方法匹配即可。
现在, 让我们看看如何去除重复代码。 对于不同的数据格式, 打开和关闭文件以及抽取和解析数据的代码都不同, 因此无需修改这些方法。 但分析原始数据和生成报告等其他步骤的实现方式非常相似, 因此可将其提取到基类中, 以让子类共享这些代码。